| 书目名称 | Data Analysis, Machine Learning and Knowledge Discovery | | 编辑 | Myra Spiliopoulou,Lars Schmidt-Thieme,Ruth Janning | | 视频video | | | 概述 | Focus on the commonalities concerning data analysis in computer science and in statistics.Emphasis on both methods (statistical analysis and machine learning) and applications (marketing, finance, bio | | 丛书名称 | Studies in Classification, Data Analysis, and Knowledge Organization | | 图书封面 |  | | 描述 | Data analysis, machine learning and knowledge discovery are research areas at the intersection of computer science, artificial intelligence, mathematics and statistics. They cover general methods and techniques that can be applied to a vast set of applications such as web and text mining, marketing, medicine, bioinformatics and business intelligence. This volume contains the revised versions of selected papers in the field of data analysis, machine learning and knowledge discovery presented during the 36th annual conference of the German Classification Society (GfKl). The conference was held at the University of Hildesheim (Germany) in August 2012. | | 出版日期 | Conference proceedings 2014 | | 关键词 | Applied Statistics; Classification; Clustering; Data Analysis; Prediction | | 版次 | 1 | | doi | https://doi.org/10.1007/978-3-319-01595-8 | | isbn_softcover | 978-3-319-01594-1 | | isbn_ebook | 978-3-319-01595-8Series ISSN 1431-8814 Series E-ISSN 2198-3321 | | issn_series | 1431-8814 | | copyright | Springer International Publishing Switzerland 2014 |
The information of publication is updating

书目名称Data Analysis, Machine Learning and Knowledge Discovery影响因子(影响力)

书目名称Data Analysis, Machine Learning and Knowledge Discovery影响因子(影响力)学科排名

书目名称Data Analysis, Machine Learning and Knowledge Discovery网络公开度
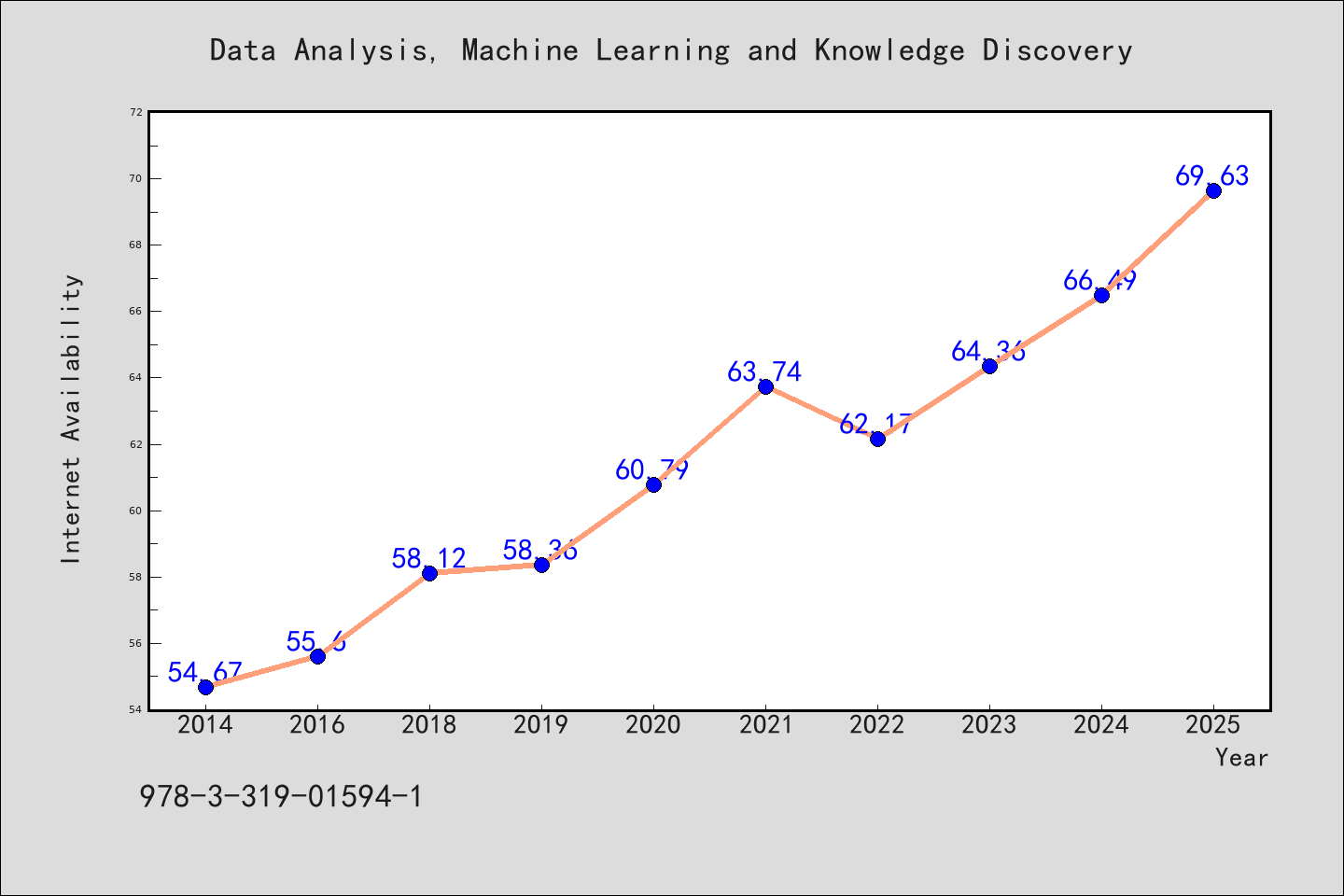
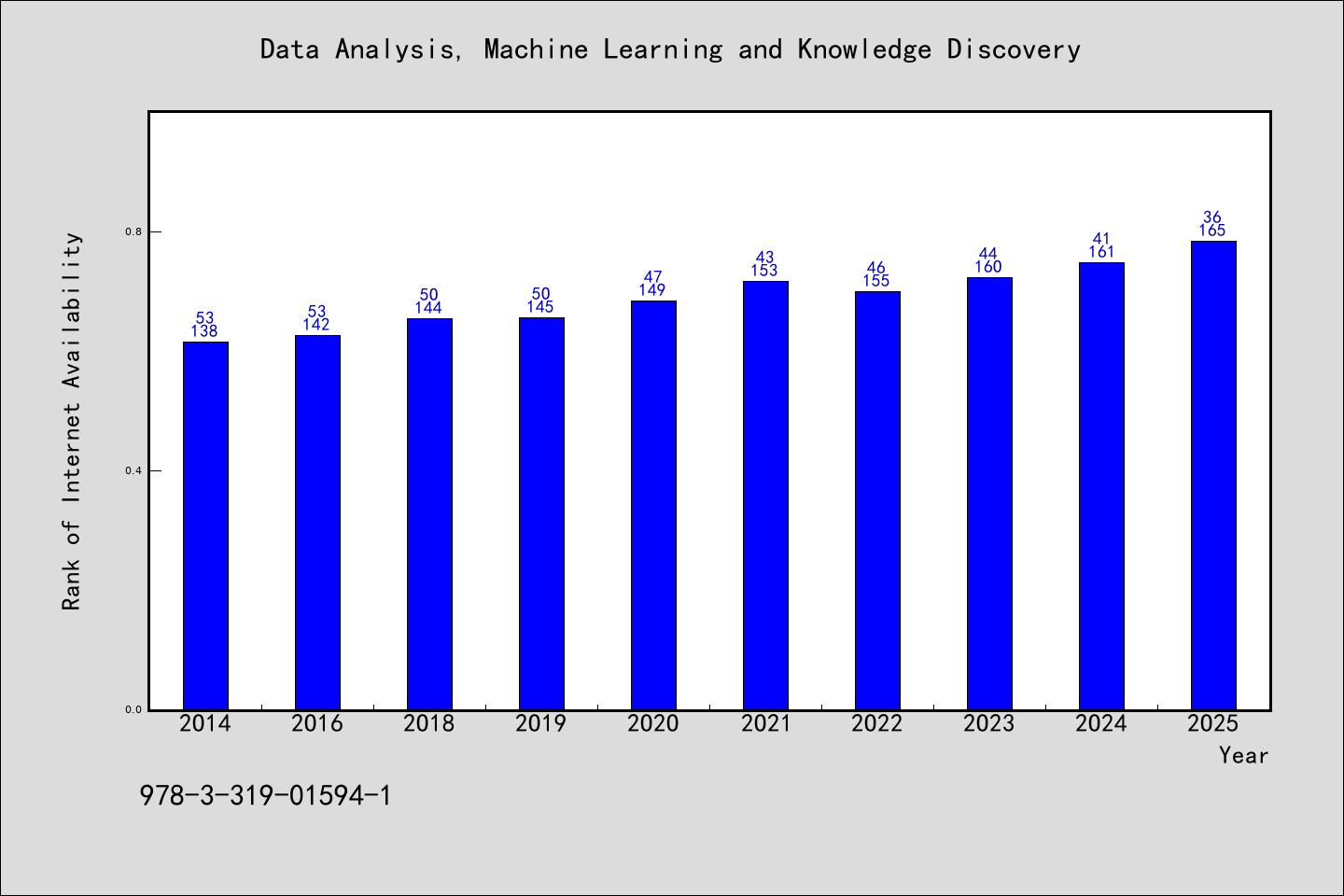
书目名称Data Analysis, Machine Learning and Knowledge Discovery网络公开度学科排名
书目名称Data Analysis, Machine Learning and Knowledge Discovery被引频次

书目名称Data Analysis, Machine Learning and Knowledge Discovery被引频次学科排名

书目名称Data Analysis, Machine Learning and Knowledge Discovery年度引用

书目名称Data Analysis, Machine Learning and Knowledge Discovery年度引用学科排名

书目名称Data Analysis, Machine Learning and Knowledge Discovery读者反馈

书目名称Data Analysis, Machine Learning and Knowledge Discovery读者反馈学科排名

|
|
|





 发表于 2025-3-21 16:45:02
发表于 2025-3-21 16:45:02



